NÜWA: Visual Synthesis Pre-training for Neural visUal World creAtion
Contributor:
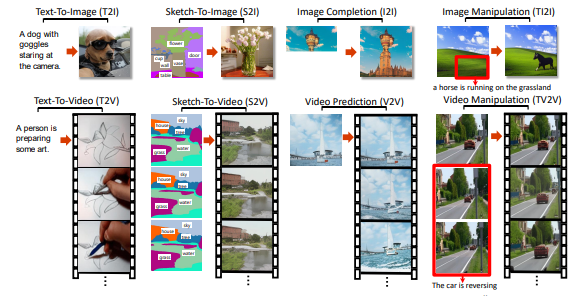
Summary
Images in dataset
Year Released
Key Links & Stats



Contributor:
Images in dataset
Year Released